
main content start
Portfolio News
UNICEF Innovation Fund: Thinking Machines
Thinking Machines
Data Science+AI
Philippines
Apr 04 , 2018
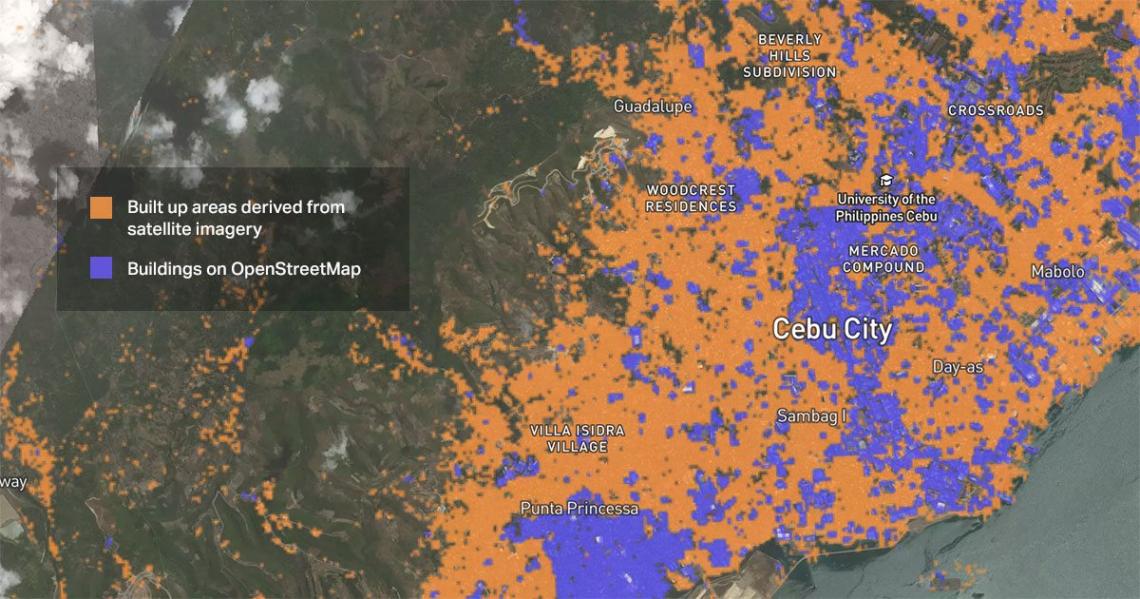
Thinking Machines: Developing OnTrackPH – a robust record matching engine and web tool optimizing huge numbers of records and datasets.


We believe in open data, open source, open AI, and building great technology ecosystems.
Related Stories


Portfolio News
June 17, 2026

Portfolio News
June 17, 2026

Portfolio News
June 17, 2026

Portfolio News
June 16, 2026
